Половина «болей» ИТ-поддержки и управления может быть решена с помощью функций зонтичного мониторинга в AIOps-решениях. Среди таких проблем — сложности в поиске решения ИТ-мониторинга, которое бы покрывало бы одновременно все потребности: в мониторинге производительности приложений, инфраструктурном мониторинге, мониторинге логов, ИБ-мониторинге. В ИТ-управлении известны два подхода к этой ситуации: стараться использовать решения одного вендора или все-таки попробовать дать каждой команде наиболее подходящий инструмент и объединить данные с помощью зонтичного мониторинга.
Среди уже более технических проблем — высокий уровень «шума» от систем мониторинга, когда среди тысяч уведомлений сложно распознать действительно важные; непонимание причины сбоя, не говоря уже об отсутствии прогнозирования инцидентов. Инженерам поддержки также сложно правильно расставлять приоритеты, потому что они не обладает инструментом оценки влияния сбоя на бизнес – например, инженер может не знать, что падение одного сервера может привести к недоступности всего сервиса. Во многих крупных и быстрорастущих компаниях перманентная борьба со сбоями становится нормой. В результате – долгий MTTR (Mean Time to Repair), финансовые и репутационные потери для бизнеса.
Функциями зонтичного мониторинга (hybrid cloud monitoring) обладают сегодня многие AIOps-решения (термин AIOps, Artificial Intelligence for IT Operations, был введен Gartner для решений, которые позволяют управлять ИТ с помощью AI-технологий). В этой статье пошагово рассказываем, как устроен и работает «зонтик» AIOps monqlab и каких результатов можно с ним достичь.
Шаг №1: сбор данных
Зонтичный мониторинг работает по принципу, когда все данные, которые могут сигнализировать о состоянии ИТ и цифровых сервисов – от данных систем мониторинга, логов и бизнес-данных – собираются и анализируются в одной системе. Таким образом, инженеры поддержки вместо 3-4 экранов, за которыми нужно постоянно следить и вручную анализировать паттерны и зависимости и прогнозировать влияние, имеют один экран, на котором отражается карта цифрового здоровья бизнеса.
В систему можно подключить абсолютно любой источник данных. Для самых популярных систем мониторинга – Zabbix, SCOM, Prometheus, ntopng, Nagios XI – уже есть преднастроенные коннекторы. Для остальных источников пользователь может достаточно легко создать свой коннектор.
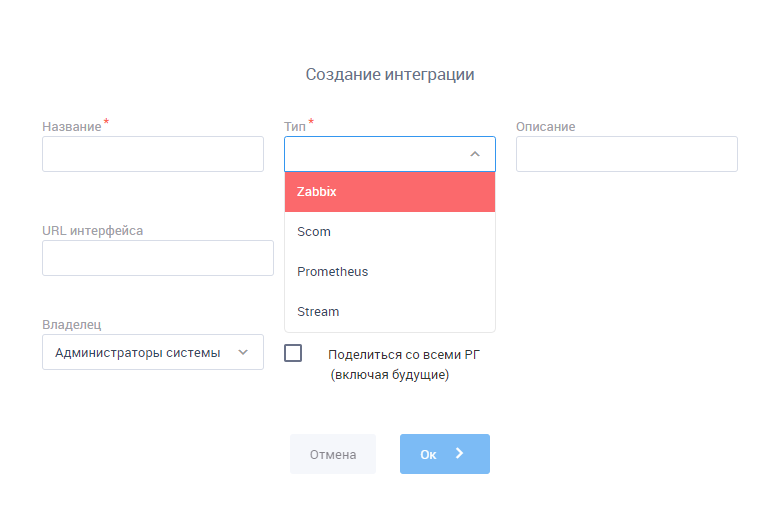
Интерфейс создания интеграции
После подключения данные начнут поступать в систему, обогащать ресурсно-сервисную модель. Они же будут базой для root-cause анализа и детектора аномалий.
Просматривать поступающие события можно на экране первичных событий. Это можно делать как в реальном времени, так и выбрав определенный промежуток. По умолчанию в системе отражаются данные за последние 30 минут.
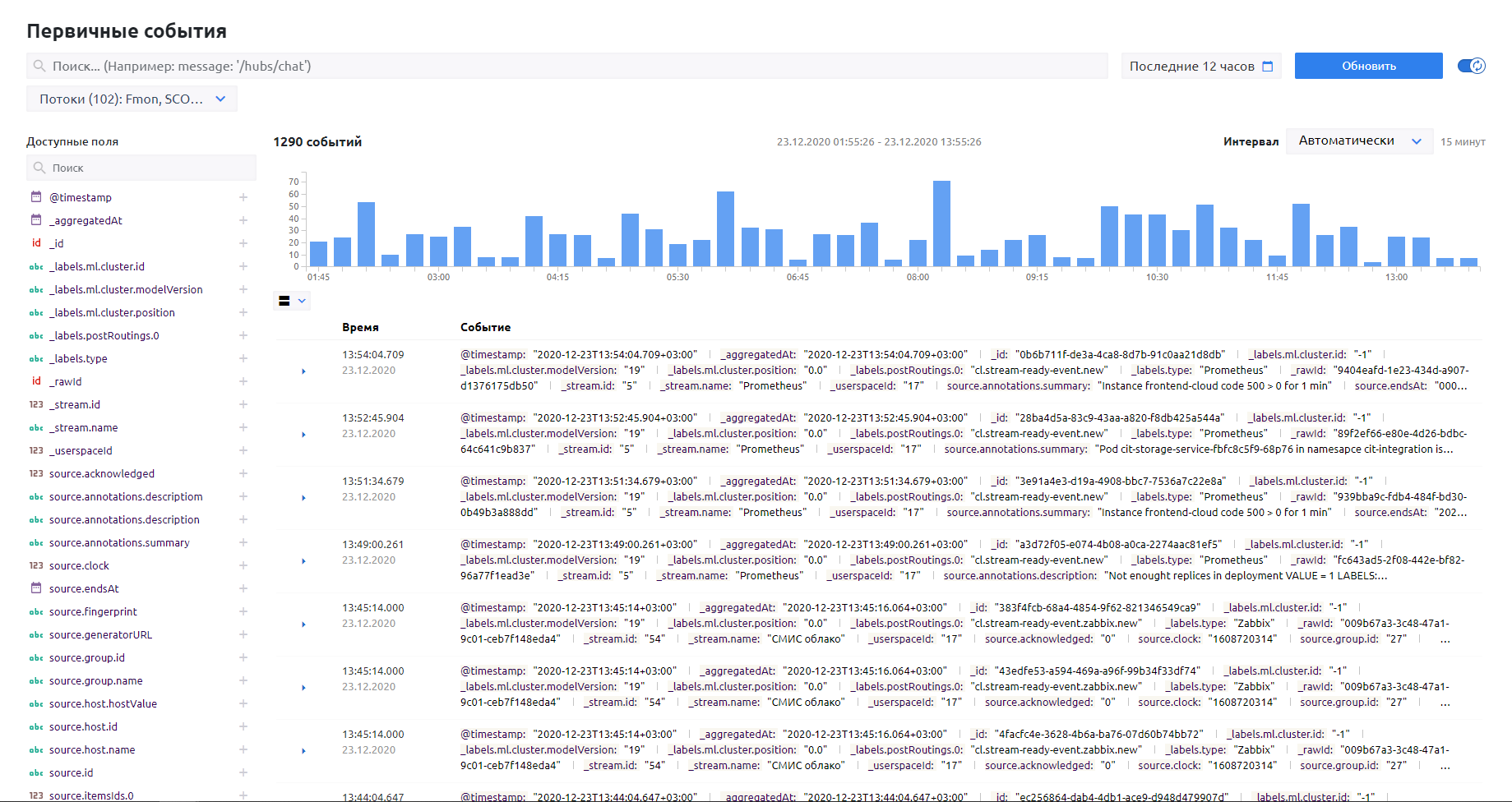
Экран анализа логов и первичных событий monqlab
События отражаются на гистограмме, которая позволяет увидеть количество сообщений, полученных из потока данных за выбранный интервал. Первичный анализ и количество сообщений об ошибке позволяет сделать выводы о возможном масштабе проблемы.
На экране первичных событий можно искать события по потокам, по ключевым словам и выражениям, по временному периоду.
Датапикер
Шаг №2. Настройка синтетических триггеров
Синтетические триггеры позволяют системе фильтровать события и понимать, как на них реагировать. Например, инженеры знают о проблемном запасном сервере, на него настроен мониторинг, но его остановка не влияет значительно на стабильность работы – значит, триггер на события, связанные с ним, можно отключить или попросить систему срабатывать только если, скажем, сервер полностью отключится.
После создания синтетические триггеры будут обрабатывать только сообщения с похожими атрибутами – таким образом, можно отсортировать схожие события и сообщения и снизить до 80% информационный шум.
Триггеры создаются через несколько простых шагов:
- Выбор шаблона: система уже «из коробки» имеет шаблоны обработки первичных событий, которые можно редактировать при необходимости;
- Конфигурация префильтра, необходимая для определения множества первичных данных, которые будет обрабатывать созданный триггер;
- Конфигурация правила, нужная для настройки поведения триггера при получении нужного первичного события или записи лога
- Отладка правила с помощью симуляции получения системой первичного события.
- Просмотр истории триггера с применением различных фильтров, от имени и времени формирования до инициатора и типа изменений.
- Управление триггером: его можно применить, клонировать или удалить.
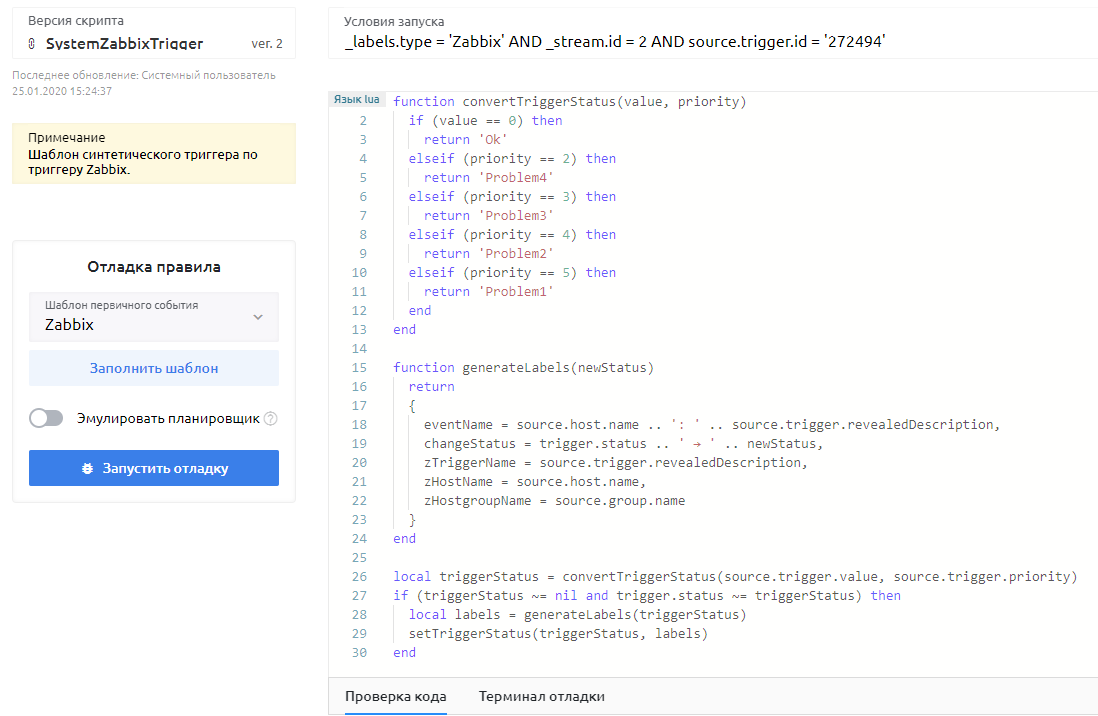
Пример кода синтетического триггера
Шаг №3. Ресурсно-сервисная модель
Ресурсно-сервисная модель, которая состоит из КЕ (конфигурационных единиц) визуализирует состояние ИТ. Сейчас в разработке находятся функции ML, которые уже в ближайшее время позволят на основе данных, поступивших в систему, спрогнозировать сбой, быстро найти его первопричину и оценить степень его возможного влияния на бизнес.
Система позволяет с помощью РСМ пользоваться результатами root-cause анализа: выявлять аномалии и связи между событиями, искать первичные события – «инициаторы» сбоя, а также искать аномалии на основе исторических данных.
Ресурсно-сервисная модель monqlab – гибкий инструмент, который адаптируется под запросы пользователи. В интерфейсе системы можно управлять масштабом графа модели и расположением вершин графа, создавать КЕ с назначением родительской и дочерней категории, связывать между собой объекты РСМ (подчинить или настроить степень влияния).
Ресурсно-сервисная модель даёт возможность визуализировать и отслеживать состояние здоровья КЕ. Можно проследить график изменения здоровья КЕ за последние 72 часа, количество триггеров и список других единиц. Система позволяет также управлять критичностью нижестоящих КЕ.
В РСМ можно настраивать уровни доступа для ее просмотра и управления – как для отдельных пользователей, так и для целых групп.
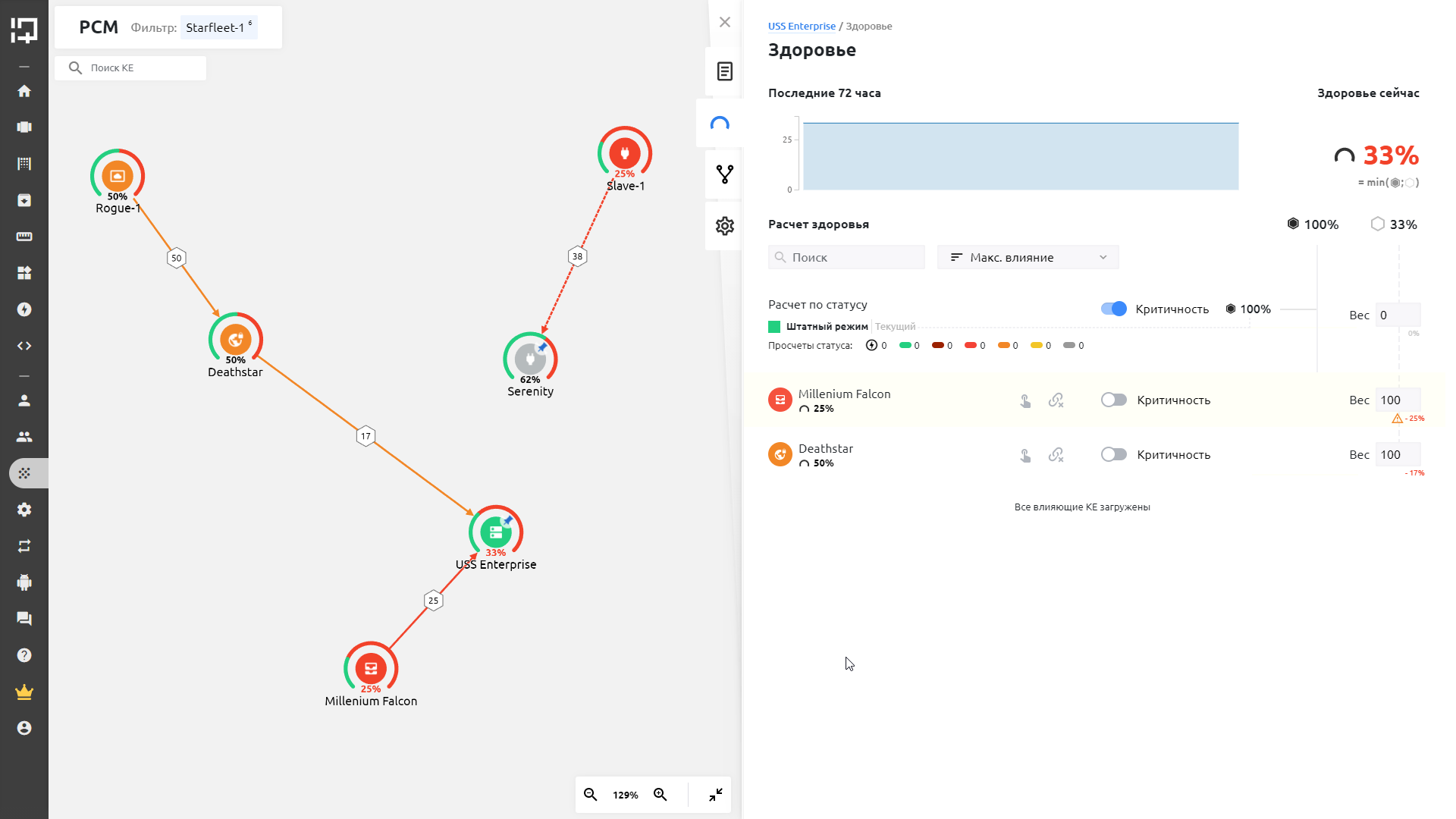
Ресурсно-сервисная модель – главный инструмент визуализации здоровья ИТ
Если говорить о комплексных возможностях РСМ, то модель позволяет:
- рассчитывать статус элементов на основе топологии, даже тех, о которых пока ничего неизвестно;
- визуализировать состояние важных бизнес-сервисов и постоянно отслеживать их состояние;
- получать более точных исходных данных при помощи математической модели;
- контролировать аномалии и оперативно реагировать на первопричины;
- отфильтровать несущественные события;
- проводить визуальную оценку бизнес-процессов и их влияния на весь бизнес;
- рассчитывать влияние различных элементов на разные бизнес-уровни;
- выстраивать цепочки влияния и подчинения.
Шаг 4. Визуализация данных в РСМ: главный и оперативный экраны
После настройки РСМ пользователь получает возможность работать с обогащенными данными и выявленными проблемами на главном и оперативном экранах.
1. Главный экран.
На главном экране доступны:
- шкала времени, которая позволяет менять период, за который выводится информация для блоков Статус во времени и События во времени. Границы и промежутки времени можно настраивать
- список КЕ и фильтры к ним: можно выбрать систему или группу систем, по которым будут отображаться события. Можно выбрать приоритет отражаемых событий и указать их длительность
- персональные фильтры (по приоритету, типу КЕ, фильтру элементов, списку КЕ, кнопкам взаимодействия и др.)
Главный экран позволяет показывать, например, только системы с проблемами. Системы, в которых не зафиксированы события за выбранный промежуток времени, отображаться не будут.
На главном экране можно также воспользоваться виджетами:
- «Статус во времени». Он позволяет видеть состояние всех систем за выбранный промежуток времени. Красным отражаются системы с критичными проблемами, желтым – системы с проблемами среднего приоритета, зеленым – «здоровые».
- «События во времени», которые отображает информацию о количестве активных событий в течение определенного периода. События при этом разделяются по приоритету с помощью фильтром – если, например, в фильтре установлено отображение событий только 1-го приоритета, то события более низких приоритетов не будут отображены.
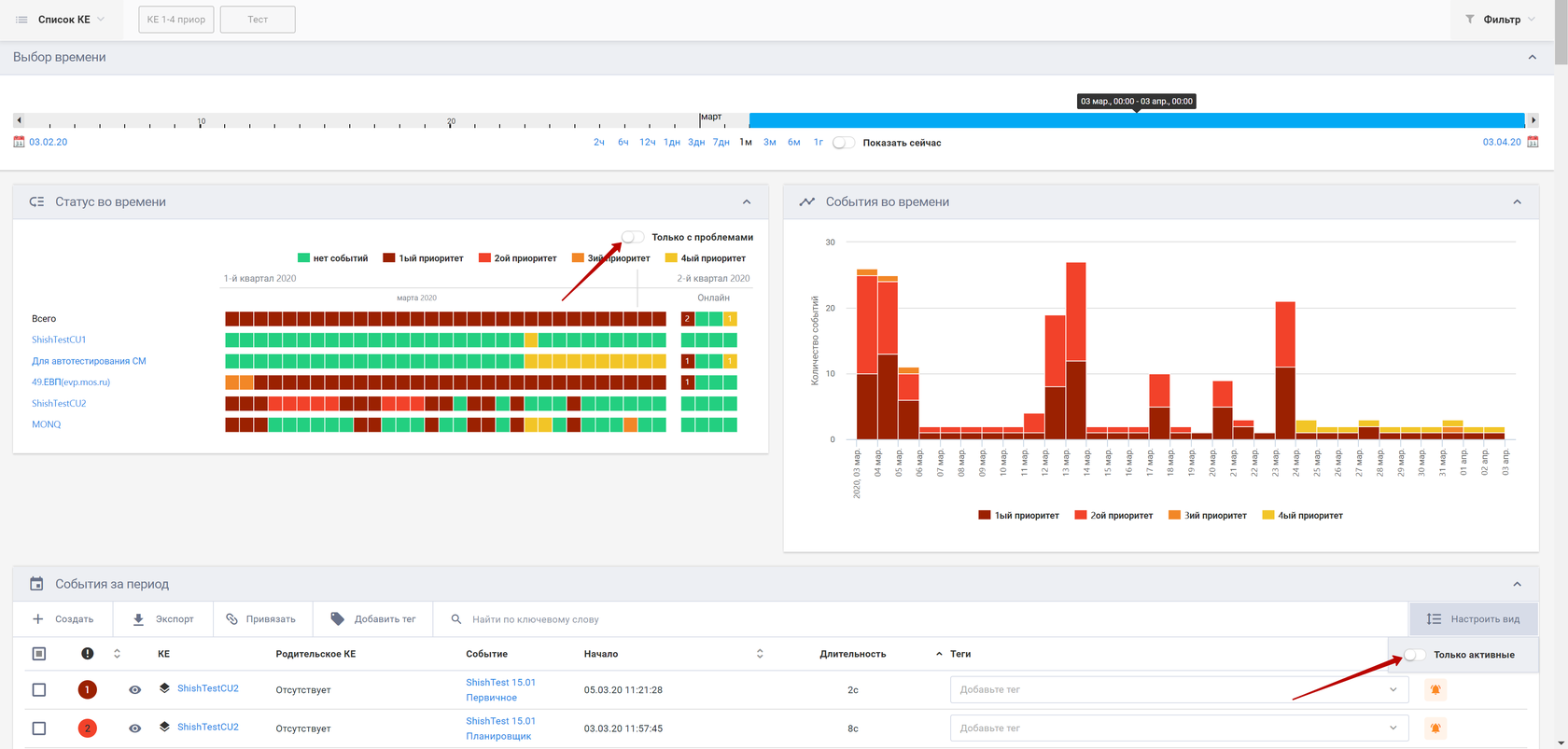
Виджет отражения событий только с проблемами
3. «События за период». Виджет дает возможность быстро просматривать события за период времени, создать оповещение по ним или зарегистрировать инцидент в системе Этот же виджет позволяет выгрузить события в .csv и .xlsx.
4. Фильтрация событий по активным и не активным.
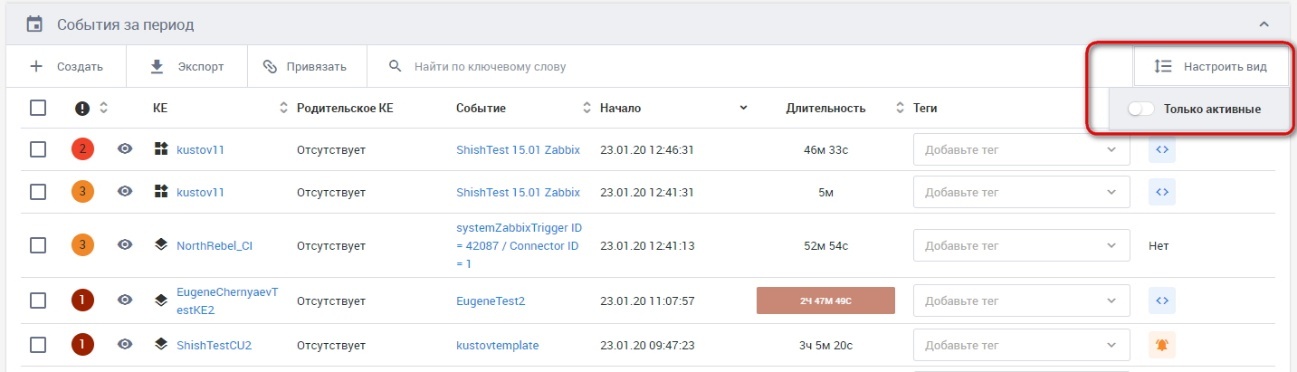
Виджет отражения только активных событий
Отфильтровать события в РСМ можно по нескольким параметрам:
- по части или полному имени события
- по приоритету
- по КЕ
- по родительскому КЕ
- по началу или длительности события
- по действиям (произведено оповещение пользователей, произведена регистрация инцидента, производилось выполнение скриптов).
В системе доступны две системы управления оповещения о событиях и их регистрация в ITSM: ручная и автоматическая.
2. Оперативный экран.
На оперативном экране отражаются активные события и те, что завершились не более 15 минут назад. Этот экран позволяет без установки фильтров на главном экране сразу увидеть текущее состояние ИТ-инфраструктуры и цифровых сервисов.
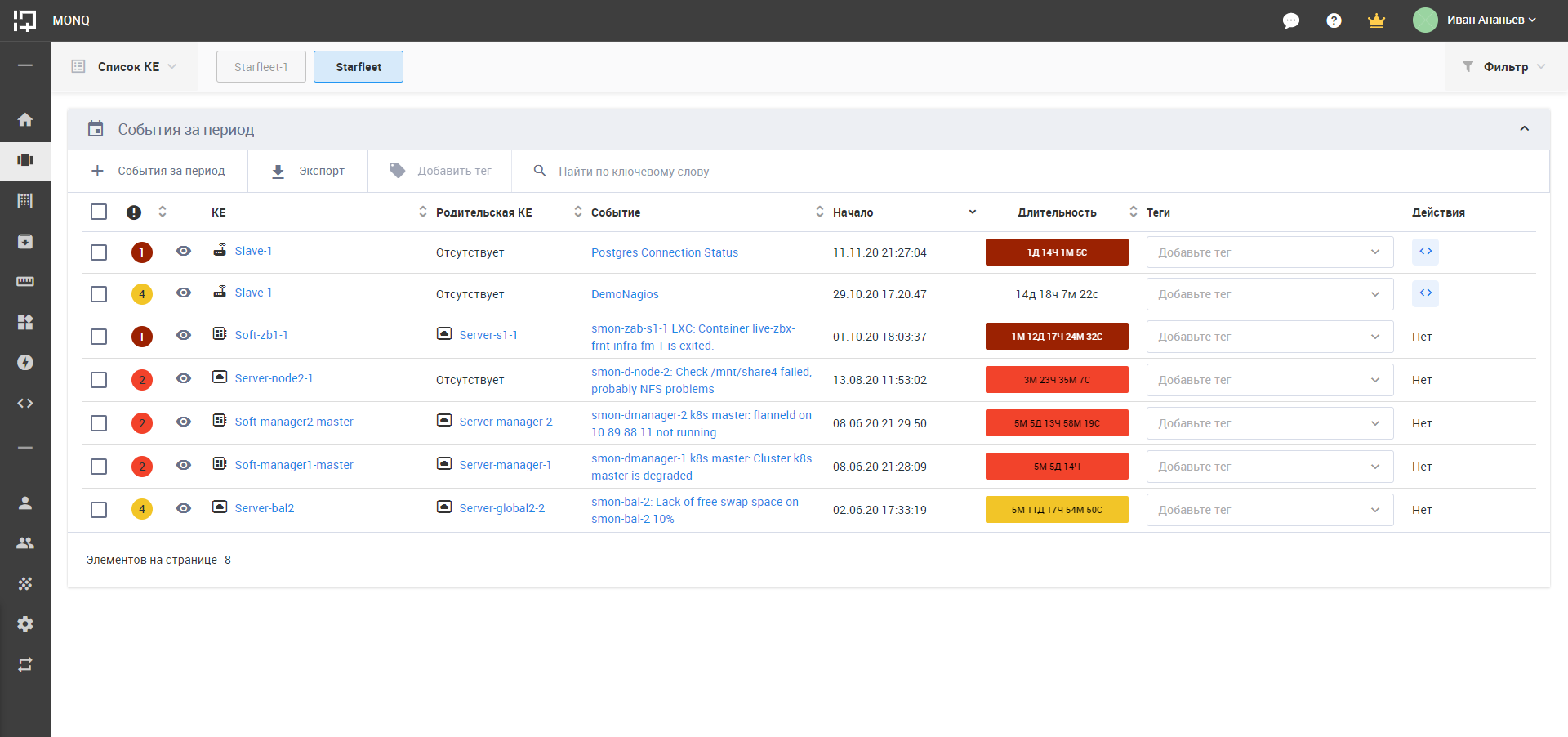
Оперативный экран
Шаг 5. Автоматизация рутинных действий
Последний шаг в настройке и использовании зонтичного мониторинга – автоматизация рутинных действий, которая помогает при наступлении определенных событий автоматически регистрировать события, оповещать ответственных, запускать скрипты автохилинга и систему автоэскалации. Настройка уведомлений гибкая – можно настраивать частоту, срочность, список лиц с учетом их отпуска, а также способ доставки – в мессенджеры, по телефону, на рабочую почту.
В системе за эти функции отвечают два блока функционала:
1. «Правила», куда можно перенести регистрацию инцидентов в service desk, добавить их к рабочей группе, создавать списки рассылок оповещений о событиях и настраивать их параметры. К правилам обработки инцидентов можно добавлять одно или несколько условий с разными параметрами – от КЕ и графа влияния до приоритета, источника события, степени влияния и т.д.
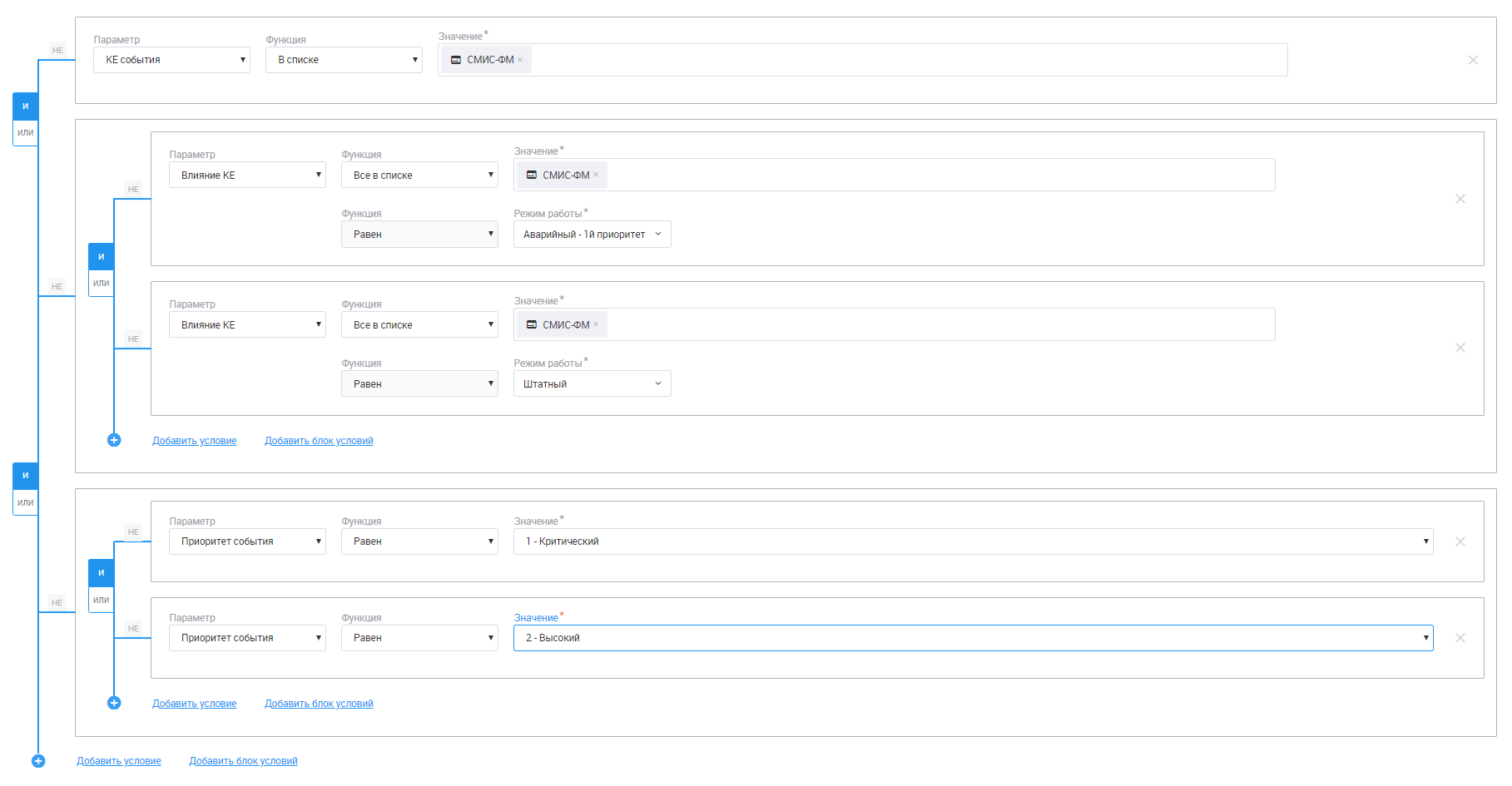
Пример настройки правила
2. «Действия» помогают настроить список определенных действий, которые система будет выполнять при срабатывании правила. Стандартных действия три:
а) оповещение – уведомление операторов по спискам рассылок;
б) регистрация инцидента в HPSM по шаблону;
в) закрытие инцидента в HPSM по шаблону.
Функционал позволяет выбрать время активности, когда операции по обработке событий выполнять не требуется, или отложить выполнение какой-либо операции. Шаблоны текста оповещений и регистрации инцидентов в HPSM можно редактировать внутри системы.
Однотипные правила и действия создавать заново не нужно – можно просто их клонировать.
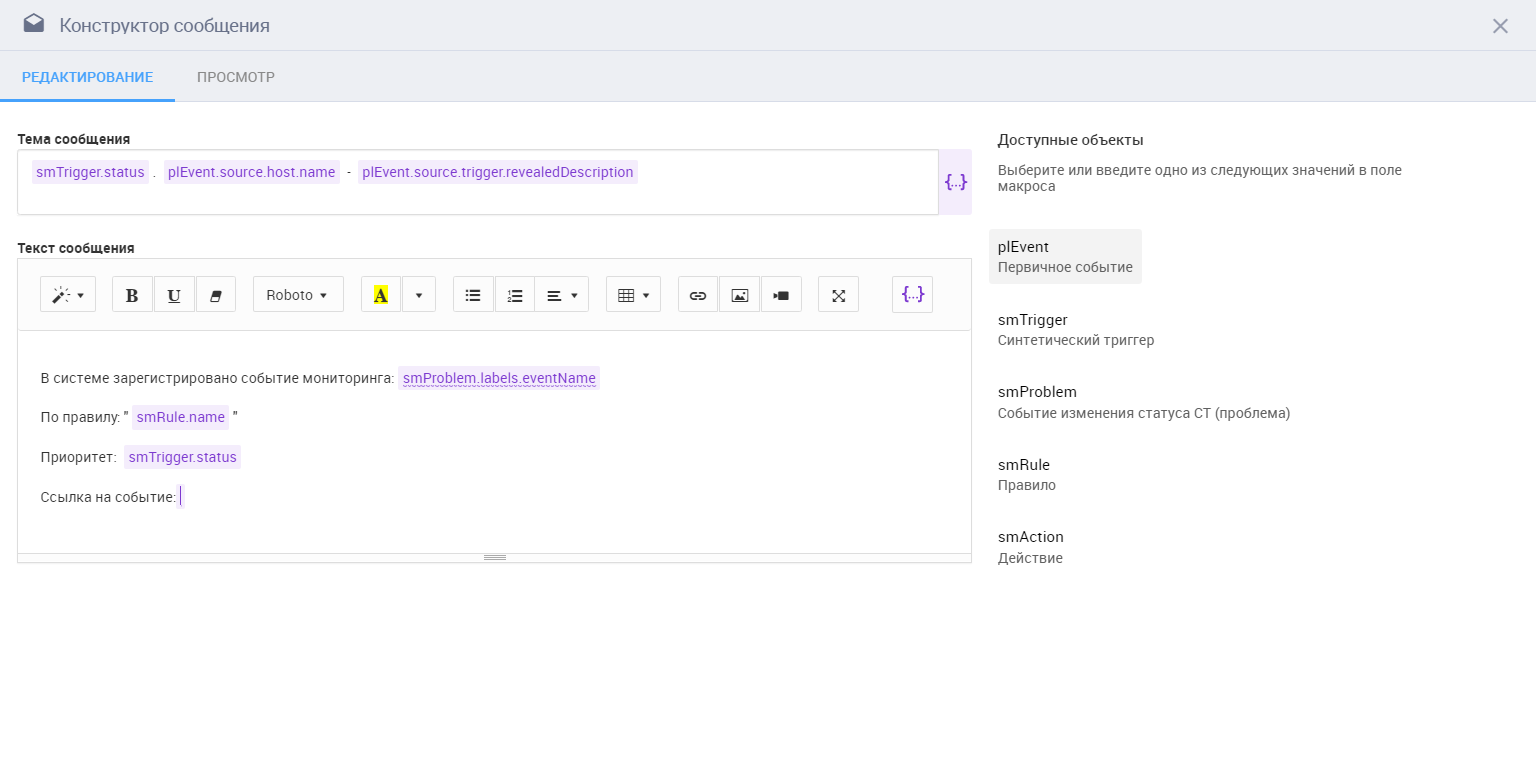
Редактор конструктора сообщений
Каких результатов можно достичь с помощью такого функционала?
Давайте разберем кейс одного из наших клиентов – крупной госкорпорации, цифровыми сервисами которой ежедневно пользуются >1 млн пользователей. Для понимания объемов цифровой инфраструктуры – у компании 35 независимых бизнес-юнитов, а объем ежедневно обрабатываемых триггеров и событий достигает 35 000 в сутки.
Клиент столкнулся с типичными для крупных цифровых компаний проблемами:
- Пользователи замечали сбои раньше ИТ, инциденты решаются долго: цифровые сервисы и ПО для сотрудников работали нестабильно, внешние и внутренние пользователи жаловались на недоступность. Критические инциденты обрабатывались более 30 минут, иногда до 1 часа.
- Высокие затраты на ИТ-мониторинг. В случае обнаружения сбоя работа с инцидентом (назначение задачи, уведомление ответственных) происходила вручную и занимала много времени.
- Много шума от систем мониторинга, общее состояние ИТ непонятно. Только по одной информационной системе могли приходить в день по несколько сотен оповещений. Было непонятно, какие их них особенно важные и на какие нужно реагировать быстрее, а какими можно заняться позже.
В результате внедрения зонтичного мониторинга клиент получил:
- Единый экран работы с инцидентами, подключив к «зонтику» все системы мониторинга и логи. Система автоматически группирует события, назначает важность в зависимости от потенциального уровня угрозы от сбоя. Настроили автокластеризацию и дедубликацию событий
- Автоматизированный инцидент-менеджмент. Настроили автоэскалацию событий, их автоматическую регистрацию в ITSM, оповещение ответственных команд, подсказки для инженеров по разрешению проблем, скрипты автоматизации для рутинных задач.
- Ресурсно-сервисная модель. Настроили ресурсно-сервисную модель, которая визуально показывала текущее состояние здоровья всех ИТ систем на одном экране. Ресурсно-сервисная модель позволяла видеть, падение каких сервисов может критично повлиять на доступность цифровых сервисов и правильно расставлять приоритеты в решении инцидентов. Один из пользователей системы так описывает возможности РСМ: «Мы пробовали и другие решения, потому что у них можно было тоже выстроить ресурсно-сервисные модели и построить весь граф зависимости систем друг от друга, от информационных узлов, понять, как они влияют друг на друга. Но там все это строится на тяжелом программировании или сложной настройке с жесткими ограничениями по типу связей, архитектуре модели и типу конфигурационных единиц, а также требует дополнительной поддержки от вендора. В monqlab ресурсно-сервисную модель можно создать за 10 минут без навыков программирования – создать модель, привязать тесты, запустить их и настроить автоматизированные правила оповещения нужных команд, которые участвуют в проекте, а также произвести регистрацию инцидента в нашей ITSM с последующей визуализацией в системе хода решения проблемы. Настройка оповещений очень гибкая: если, например, сбой 5 минут – оповещение по почте, если больше 5 минут – отправляем сообщение, если больше 10 минут – официально регистрируем. У других систем таких возможностей в коробке мы не нашли".
- Визуализация и карта здоровья. Клиент получил инструменты продвинутой визуализации. По графу зависимостей можно было настроить триггеры и объединять события.
- Интеграция с ITSM, которая позволила многократно увеличить количество создаваемых инцидентов: автоматически в сутки создавали в среднем 28. Раньше на создание одного инцидента уходило примерно 20 минут времени одного сотрудника ситуационного центра. Чтобы отрабатывать такие же объемы, как это делает monqlab, клиенту понадобилось одновременно работающих 10 сотрудников в день.
- Оповещение ответственных и уровни критичности. Все проблемы фиксируются, ответственные моментально уведомляются о важных событиях. Клиент как оператор системы сам определил список ответственных лиц, кому уходят оповещения — подрядчикам, непосредственно отвечающим за систему, и всем тем, кому нужно быть в курсе, что что-то не так. Использовали различные виды оповещений — на электронную почту и в мессенджеры. Настроили критичность оповещения: ввели 4 вида оповещений, от высокого до низкого приоритета, соответственно, с разным уровнем ответственности. В самом оповещении есть информация, какого оно приоритета, и сразу понятно, насколько оперативно на это нужно реагировать.
Каких показателей это помогло достичь?
- Доступность сервисов выросла до 98.5% (на 1.2% с 97.3%)
- Снижение объема жалоб на недоступность в 8 раз
- Двукратное увеличение средней скорости решения сбоя (с 30-60 минут до 15 минут)
- На 30% меньше затрат на ИТ-поддержку, так как меньше инженеров занято на обработке инцидентов
- В 2 раза меньше сотрудников, занятых в процессах мониторинга
- Реорганизация ситуационных центров. Два из трех ситуационных центра реорганизовали из диспетчерских в рабочие группы продуктов, которые не просто смотрят в экраны, а совершают полезные действия.
- На 64% снизили количество ложных срабатываний за счет сложной логики обработки.
- Понятно влияние сбоя на компанию. Стало ясно общее состояние ИТ и степень возможного влияния сбоя на стабильность работы сервисов.
Узнать о monqlab больше можно на бесплатной демонстрации системы.